KAMET: Contenido, Usos y Modelación del Conocimiento
Osvaldo Cairó
Departamento Académico de Computación
División Académica de Ingeniería
ITAM
PROYECTO REDII
1999 - 2000
|
TITULO DEL PROYECTO: |
KAMET: Contenido, Usos y Modelación del Conocimiento. |
|
DATOS DEL RESPONSABLE: |
Dr. Osvaldo Cairó Battistutti e-mail: cairo@lamport.rhon.itam.mxhttp://cannes.divcom.itam.mx/Osvaldo |
|
INSTITUCION: |
División Académica de Ingeniería - ITAM |
|
DIRECCION COMPLETA: |
Río Hondo 1 - 01000 Progreso Tizapán - México D.F. |
1. LINEAS DE INVESTIGACION
Se describe a continuación la línea de investigación seguida en el período. La descripción se divide en tres partes. En la primera, se presentan los objetivos y metas iniciales del proyecto. En la segunda parte, se presenta brevemente el estado del arte en el área del proyecto y como se incorpora KAMET a dicho contexto. Finalmente en la tercera parte, la más extensa, se describen algunos puntos en los cuáles se ha trabajado intensamente en el último año.
1.1. OBJETIVOS Y METAS INICIALES
La adquisición del conocimiento ha sido reconocida en los últimos años como la etapa crítica y fundamental, y el cuello de botella para la construcción de Sistemas Basados en Conocimientos (SBC). Aunque las tecnologías han sido perfeccionadas y el desempeño de los SBC ha evolucionado en forma notoria en los últimos años, la adquisición del conocimiento sigue siendo el principal factor que obstaculiza un buen ciclo de vida en el desempeño de un SBC.
KAMET ataca justamente el problema descrito: falta de métodos apropiados para la modelación del conocimiento, herramientas para manejar esos métodos, y concepciones para analizar e interpretar el conocimiento. KAMET es una metodología basada en modelos diseñada para manejar la adquisición del conocimiento de múltiples fuentes de conocimiento. Es un método robusto que permite realizar la adquisición del conocimiento en forma incremental y en un ambiente de cooperación. El objetivo de KAMET, y por lo tanto del proyecto, es en cierto sentido, mejorar las fases de adquisición y modelación del conocimiento haciendo a éstas más eficientes. Se describen más adelante específicamente las tareas que se desarrollarán para alcanzar estos objetivos.
1.2 INTRODUCCION
El inicio de la década de los ochenta marcó el boom de los Sistemas Basados en Conocimiento, así como herramientas para su construcción, y un buen número de técnicas para adquirir, validar y verificar el conocimiento involucrado en un SBC. Desde entonces y hasta la fecha miles de SBC han sido desarrollados y aplicados en muy diversas áreas del conocimiento, principalmente en finanzas, manufactura industrial, sistemas gerenciales, calendarización y controladores de vuelo, servicios al cliente, industria militar, etc. A pesar de que las tecnologías usadas fueron perfeccionándose, el problema esencial, y el cuello de botella en el desempeño de los SBC era, en aquel entonces y lo sigue siendo aún, la adquisición de conocimiento.
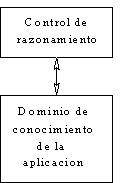
La necesidad de la industria durante la primera mitad de la década de los ochenta era muy clara: construir un SBC de alta calidad, a gran escala y lo más importante de todo, de forma controlada. En esos primeros años de la inmersión del conocimiento en sistemas computarizados, el paradigma dominante para los sistemas basados en conocimiento era el desarrollo rápido, fast prototyping, de aplicación de una sola ejecución, usando hardware y software altamente especializado, como máquinas LISP, intérpretes de comandos para sistemas expertos (expert system shells), etc. Uno de los grandes mitos de la época, era la creencia de que la estructura de los SBC y del conocimiento mismo, era muy simple (ver figura 1).
Figura 1: La estructura básica de la primera generación de sistemas expertos.
El dominio de conocimiento de la aplicación se veía como una gran bolsa de hechos y reglas del dominio de aplicación, controlados por un simple motor de razonamiento o inferencia. Durante los últimos 15 años, muchos desarrolladores y administradores han comenzado a notar la necesidad de utilizar un enfoque estructurado para analizar, diseñar y administrar un SBC, al igual que muchos otros sistemas de información. Por si fuera poco, la arquitectura del conocimiento ha resultado ser mucho más compleja y dependiente del contexto de lo que fue sospechado por la primera generación de sistemas expertos. De esta forma, la construcción de un SBC, pasó de ser un arte a convertirse en una disciplina formal, sin embargo, no fue un proceso rápido: más de 10 años se necesitaron para transformar las primeras técnicas de modelado y creación de SBC que surgieron a final de la década de los ochenta, en metodologías maduras para Ingeniería y Adquisición de Conocimiento.
La metodología para adquisición de conocimiento, KAMET, nace durante el último tercio de la década de los noventa. El ciclo de vida de la primera versión de KAMET, estaba constituido principalmente por dos fases: una para analizar y adquirir el conocimiento de las distintas fuentes involucradas en el sistema y una segunda fase para modelar y procesar dicho conocimiento. El mecanismo propuesto en KAMET para adquirir conocimiento, se basaba en refinamientos progresivos de modelos, lo que permitía de manera incremental refinar el conocimiento y obtener su estructura óptima. KAMET estaba inspirado en dos ideas básicas: el modelo de espiral propuesto por Boehm, y la esencia del proceso cooperativo. Ambas ideas, estrechamente relacionadas con el concepto de reducción de riesgos.
Para alcanzar sus objetivos, junto con KAMET fueron incluidas muchas herramientas para adquirir conocimiento, estrategias para reducir riesgos en la forma de validación y verificación, técnicas para estimación de costos y tiempos, etc. Esto tuvo ventajas y desventajas. Ventajas, en el sentido de que se dotaba a KAMET con una completez difícilmente igualable. Pero, por otra parte, incrementaba la complejidad de la metodología y dificultaba su aplicación, ya que sus usuarios podían perder de vista la estructura básica de la metodología y aplicarla incorrectamente. Fue éste el motivo principal por el cual decidimos revisar la metodología, y después de evaluar rigurosamente todos los parámetros involucrados, decidimos separar la metodología en varias capas. En este informe, hablaremos acerca de las mejoras realizadas a KAMET, los problemas que enfrentamos, las líneas de investigación que seguimos y los logros obtenidos.
Cairó, O. (1998). KAMET: A Comprehensive Methodology for Knowledge Acquisition from Multiple Knowledge Sources. Expert System with Applications, 14(1/2), pp1-16. Pergamon. ISSN 0957-4174.
Cairó, O. (1998a). The KAMET Methodology: Content, Usage and Knowledge Modeling. In Gaines, B. & Mussen, M. (Eds.). Proceedings of the 11th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW´98). SRGD Publications, Department of Computer Science, University of Calgary. Proc-1, pp1-20.
1.3 KAMET: LA NUEVA GENERACION
Nuestra meta era muy ambiciosa. Un enfoque conocido como 80-80: KAMET debía funcionar para 80% de las aplicaciones y para 80% de los trabajos de modelado. Para alcanzar este objetivo, y poder adaptar KAMET a un número, siempre creciente de SBC, dividimos la metodología en varias capas. La primera, en la base de la pirámide, representa la forma general de la metodología misma, se piensa en ella como el mapa del camino, una guía para desarrollar SBC. La segunda capa proporciona los medios de transporte. Es a través de éstos, que el líder del proyecto (project manager, PM) puede estimar y controlar los riesgos involucrados en el proyecto: herramientas para estimaciones de tiempo y costos, herramientas para generación de diagramas y esquemas, nuestro nuevo y mejorado animador de modelos de representación de conocimiento, herramientas para medición y métricas, etc. son algunas de las herramientas incluidas en esta segunda capa. Finalmente, la tercer capa representa una especificación técnica detallada, en forma de modelos, de un SBC (figura 2).
El ciclo abstracto de vida de KAMET
La primera capa de KAMET, representa el soporte para todos los demás niveles: el ciclo abstracto de vida. Esta capa, es una descripción de las cuatro etapas, la planeación estratégica del proyecto, la construcción del modelo inicial, la creación del modelo de retroalimentado, y por último la creación del modelo final. El ciclo de vida de KAMET es modelado usando UML, uno de los lenguajes de modelado más usados hoy en día. Intercalado con las descripciones en UML, se hace referencia además a herramientas auxiliares, proporcionando así puntos de revisión y de incorporación de material proveniente de ellas.
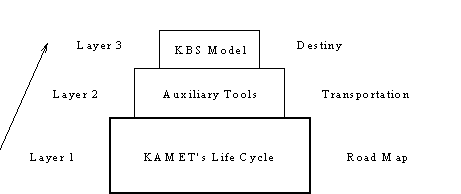
Figura 2. Capas de KAMET
KAMET sigue un modelo general de evaluación, en el cual se utilizan puntos de evaluación. En dichos puntos de evaluación, el desarrollo de los modelos no se detiene, pero grupos de auditoría externos tienen acceso al desarrollo y tienen una esquema de qué deben medir y en qué estado debe estar. Los resultados obtenidos de estas auditorias, son incorporados nuevamente a la ruta de desarrollo principal de KAMET, y nuevos puntos de evaluación son generados. Esto permite de manera incremental mejorar la detección de errores y obtener medidas más realistas tanto del consumo de recursos, como del nivel de avance del sistema.
La salida de KAMET incluye tanto diagramas en UML, como en el lenguaje de modelado de KAMET. Ambos tipos de diagramas pueden (y deben) ser controlados inmediatamente para validar su consistencia y pertinencia, los primeros utilizando los sistemas para validación de UML, y los segundos utilizando el animador de modelos, un sistema de objetos muy poderoso que traduce diagramas en el lenguaje simbólico de KAMET en código ejecutable que resalta posibles inconsistencias en la modelación del conocimiento. Se presenta brevemente la primer etapa por ser considerada fundamental para la primer capa.
Etapa 1: La Planeación Estratégica del Proyecto
La primer etapa de la primer capa constituye el alma de KAMET. Durante esta etapa muchos pasos son realizados, teniendo como meta la producción de los siguientes:
- La documentación del proyecto, y
- el plan de acción de KAMET.
En esta etapa se implementa lo que se conoce como especificación de requerimientos en ingeniería de software (IS), junto con los análisis de organización e información, provenientes de la teoría de manejo del conocimiento (KM). Los pasos que conforman esta etapa (figura 3) se deben aplicar de arriba hacia abajo, considerando que aquellos pasos que se encuentren al mismo nivel pueden ser realizados simultáneamente sin mayores complicaciones.
Los pasos en esta etapa intentan responder preguntas muy importantes acerca de la viabilidad del proyecto, cada paso puede (y debe) ser visto como una pieza de un gran rompecabezas. Si no se puede completar el rompecabezas que conforman estos pasos, entonces el conocimiento involucrado en el proyecto es demasiado general o complejo para ser modelado. Este es el primer filtro de detección y mitigación de riesgos en KAMET.
Se presenta a continuación una breve discusión de algunos puntos relevantes de la primer etapa.
- Análisis del Problema:
¿Es éste un problema con alto contenido de conocimiento? ¿Podemos generalizarlo? ¿Es éste una instancia de una familia de problemas? ¿Un SBC nos ayudará a mitigar o resolver el problema? En este paso analizamos la situación global, la especificación de requerimientos, las metas propuestas, las precondiciones, las postcondiciones, los estándares de desempeño, etc., relacionados con el problema.- Análisis Organizacional: ¿De qué forma este problema impacta a nuestra organización? ¿Puede un SBC ser ajustado a la organización, tal y como ésta se encuentra actualmente? ¿Qué tanto nos costará? ¿Debemos aplicar medidas reorganizativas al interior de la organización? Debe analizarse cuidadosamente cuál es el estado del ambiente global, y cuáles son las oportunidades reales que un SBC como el propuesto tienen en el mercado actual. Hoy en día, el conocimiento es visto como una ventaja industrial, sin embargo, las organizaciones deben estar preparadas para admitir la entrada de dicho conocimiento en sus procesos internos, de otra forma, éste se perderá irremediablemente.
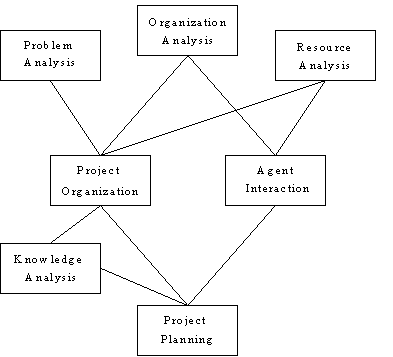
Figura 3. Pasos de la primer Etapa
- Análisis de Recursos: ¿Tenemos el equipo de desarrollo adecuado? ¿Las fuentes de conocimiento están disponibles? ¿Cuánto tiempo nos llevará construir el SBC? No debemos olvidar que hay un mercado para el conocimiento: competencia, oportunidad, restricciones de tiempo, análisis de rendimiento, etc. son elementos que no podemos dejar de lado, y son los que se analizan en este paso para poder responder las preguntas.
- Organización del Proyecto: ¿Cómo debemos poner a trabajar cada parte para que el sistema final funcione? Deben especificarse claramente y estimar los costos y efectos que cada submeta puede tener, y delegar responsabilidades para reducir la posibilidad de malos entendidos, o demoras en la construcción del sistema.
- Interacción entre Agentes: ¿Qué hace cada agente? ¿Quién es quién? Agentes son todos aquellos actores que realizan funciones útiles en la organización. Pueden ser personas, sistemas de información o bien otros SBC, capaces de realizar, en un tiempo razonable, las tareas que les hayan sido encomendadas. Es de esperarse que estos agentes actúen con un cierto grado de libertad, aunque líneas de mando y comunicación deben ser claramente identificadas para facilitar y promover el intercambio interno de información.
- Análisis del Conocimiento: ¿Cuál es la naturaleza del conocimiento? ¿Tenemos a los expertos, y otro tipo de fuentes de conocimiento disponibles? ¿El conocimiento está suficientemente estructurado como para ser manejado efectivamente? El conocimiento, el elemento más importante e intangible en el desarrollo del SBC, debe ser tratado por separado. Debe realizarse un escrupuloso análisis del conocimiento: su dominio/naturaleza, subdominios, estructura, etc., el nivel de expertiz de los agentes -ingenieros de conocimiento-. De la misma manera, la tecnología del conocimiento a nuestro alcance (técnicas y herramientas para elicitar, adquirir y modelar el conocimiento), debe ser revisada con detalle y su aplicabilidad y confiabilidad probada.
- Planeación del Proyecto: ¿Cómo debemos implementar el sistema? La única meta de este paso es recavar la documentación técnica (en forma de esquemas, planes, calendarizaciones, especificación de requerimientos, y análisis formal sobre la cual será construido el modelo inicial del sistema (en la siguiente etapa de KAMET). Dicha documentación se divide en dos partes, por un lado tenemos la documentación del proyecto, y por otra parte, tenemos el plan de acción de KAMET, un documento donde se especifican porcentajes de avance y acciones a seguir en una calendarización estricta. Las demás etapas de KAMET hacen un uso exhaustivo de tal plan, ¡implementan ese plan de acción!.
En las siguientes tres etapas de KAMET, se generan modelos a partir de la documentación de la primera etapa y se van refinando incrementalmente, hasta tener un modelo final. Sin embargo, la teoría involucrada en el desarrollo de SBC, usando KAMET, abarca tres áreas importantes: riesgos, métricas y modelación. Parte integral del desarrollo de KAMET, nos impulsó a involucrarnos en dichas áreas y producir ideas y unificar procedimientos modernos que serán incorporados a la metodología. En las siguientes secciones revisaremos estas líneas de investigación que seguimos.
1.4 RIESGOS
Todos hemos escuchado historias de errores en proyectos de software que costaron millones de dólares en una organización, mientras que dos estudiantes trabajando en una cochera construyeron un sistema superior a aquel desarrollado por un equipo profesional, y a un menor costo. ¿En verdad los proyectos de software representan un riesgo semejante? ¿Deberíamos reemplazar a nuestros equipos profesionales por hackers? Sabemos que los proyectos de software son notoriamente difíciles de manejar, en particular, aquellos que involucran conocimiento. El problema parece entonces deberse a una falta de métodos y herramientas para modelar el conocimiento.
Cada año se crean y aplican miles de SBC, algunos de ellos exitosamente, y algunos no tanto. A pesar de que hemos visto un enorme crecimiento en el desempeño de herramientas para ingeniería de conocimiento, los errores en proyectos siguen siendo una constante. El problema parece estar relacionado al mal uso de la tecnología y a un pobre entendimiento de las metodologías de ingeniería y adquisición de conocimiento. En cualquier caso, el ritmo tan alto de fracasos, no sólo en SBC sino en general en proyectos de software, está estrechamente relacionado con el concepto de riesgo. Muchos ingenieros, líderes de proyecto y diseñadores sienten que los riesgos son muy improbables como para justificar el gasto extra que representa manejarlos. ¿Conocen el significado de riesgo, o conocen las ventajas de reducción de riesgos? Seguramente sí, pero no están dispuestos a pagar el precio de localizar y manejar los riesgos. Debemos reeducarnos a nosotros mismo para ver este consumo extra de rescursos como una inversión y no al revés. En nuestra opinión, todo proyecto de software debe estar basado en:
Para alcanzar nuestra meta como diseñadores de SBC tenemos que reducir o controlar los riesgos, por lo tanto el primer paso en esa dirección es el uso de una metodología. Usar una metodología, nos permite realizar un manejo apropiado, y deja espacio para controlar el proceso, control que esencial para detectar riesgos. La mayoría de la gente usa las que han probado su efectividad en la práctica, lo cual es un buen comienzo, pero no una solución real. Las diferencias entre metodologías es enorme, por lo que es recomendable que se tomen en cuenta las siguientes consideraciones antes de optar por una u otra:
Esto puede ser un proceso que consuma mucho tiempo, ya que hay varias metodologías en el mercado, algunas de ellas tienen una buena cantidad de documentación, pero sólo unas cuantas tienen ligas a proyectos exitosos relacionados con ellas. Por lo que el mayor obstáculo es encontrar proyectos similares. Una vez que se haya seleccionado una metodología particular, se debe seguir estrictamente.
En espíritu, la mayoría de las metodologías siguen el plan para manejo de riesgos de Boehm. El cual - desafortunadamente- añade otro número de imperfecciones a la detección de riesgos, ya que la lista de riesgos propuesta por Boehm no es representativa de los riesgos que enfrentan proyectos de software, en la industria moderna. Estudios más recientes, han detectado cuáles son los riesgos más comunes en la actualidad y su importancia relativa para los líderes de proyecto. De entre estos destacan los estudios realizados por Keil, en 1998. Es importante destacar que no existe ningún mecanismo automático para detectar los riesgos más importantes del proyecto, así como tampoco lo hay para escoger la metodología más apropiada. Es responsabilidad del líder del proyecto detectar y jerarquizar los riesgos y decidir las estrategias para mitigar sus efectos. Esto pone al manejo del proyecto como el primer (y probablemente) más importante riesgo que cualquier proyecto enfrenta. Partiendo el conjunto universal de riesgos de Keil, hemos dividido el análisis de riesgos en varias secciones que analizaremos a continuación.
Mal Manejo de Proyectos
Un mal manejo del proyecto se presenta como la causa principal del número creciente de fracasos en proyectos de software. En un estudio realizado por Cole en 1995, con compañías en Inglaterra que habían sufrido errores en proyectos de software, se muestra que un 54% de ellas trataron de mejorar sus técnicas de manejo para recuperar el proyecto. Esto implica que, el líder del proyecto tenía su atención dividida entre un gran número de cosas, o que no estaba capacitado para manejar el proyecto. En cualquiera de los dos casos, debemos estar preocupados por números tan altos: más del 50% de los proyectos que se salen de control están relacionados con mal manejo del proyecto. Esto confirma el hecho de que manejar un proyecto es muy complejo. A la vez, también nos invita a revisar las prácticas actuales de manejo de proyectos.
Se sugiere entonces, con el objetivo de minimizar riesgos, que el líder del proyecto tenga las siguientes características:
- Conocedor
. Los SBC cubren el rango completo del dominio de conocimiento humano, esperar, por lo tanto, que un líder de proyecto los conozca todos es imposible. Sin embargo, es de esperarse que el líder de proyecto maneje a la perfección todas las áreas del desarrollo de sistemas: análisis de requerimientos, técnicas de diseño y modelado, herramientas para especificaciones formales, herramientas de desarrollo y lenguajes, etc.- Político
. Para que un proyecto sea viable, el compromiso de los usuarios es indispensable. Esto sólo puede lograrse por medio de una buena relación líder-usuario. Esto puede mitigar el riesgo de crear un producto que nadie usará, o un producto que no cumple los requerimientos o expectativas de nuestros usuarios.- Confiable. Una vez que hemos logrado comprometer a los usuarios con el proyecto, debemos mantener esa relación viva durante toda la fase de desarrollo e implementación. La mejor forma de lograr esto es cumpliendo con los compromisos adquiridos.
- Mente abierta. Es vital para el líder del proyecto conocer y entender lo que está construyendo.
Si el líder de proyecto sobrestima sus propias habilidades o no alcanza a comprender sus propias limitaciones, puede llevarlo a subestimar los riesgos y a fallas en el desarrollo de estrategias apropiadas para mitigar los riesgos.
Medidas para Evaluar y Manejar Riesgos
En la sección anterior nos enfocamos en el papel jugado por el líder del proyecto como una pieza clave para minimizar una de las amenazas más importantes para el éxito de un proyecto. Un líder capaz es muy deseable. Sin embargo, un SBC varía entre proyectos de mediana y gran escala, de sistemas normales a sistemas de misión o seguridad crítica. Varios individuos pueden estar involucrados en el proyecto. El líder de proyecto debe supervisar y dirigir la acción durante el desarrollo del sistema. Pero un proyecto de gran escala tiene tantos pequeños e importantes detalles, que el líder de proyecto puede, en el mejor de los casos, señalarlos y dejar que alguien más se haga cargo de ellos. Por este motivo, lograr que el equipo de desarrollo esté comprometido con el proyecto es vital.
¿Cómo podemos detectar riesgos, y cómo podemos hacerles frente? Es claro que, aún teniendo a un líder de proyecto capaz, aún tenemos un largo camino por recorrer para poder localizar todos los posibles riesgos en el sistema. Algunos de los más importantes son:
El número de cosas que pueden salir mal es innumerable, la clave para tener éxito es detectar tales cosas oportunamente, y tener al equipo apropiado para atacar esos problemas. Por tal razón, hemos dividido el espectro de riesgos en dos categorías básicas: aquellos que están bajo control directo del líder de proyecto y aquellos que están fuera de su control.
Riesgos bajo el Control Directo del Líder de Proyecto
Estos riesgos tienen que ver con el alcance, limitaciones, análisis de requerimientos, estimaciones adecuadas, elicitación del conocimiento, modelado, desarrollo de software, etc. Esto es, las cosas que el líder de proyecto, los ingenieros de conocimiento, diseñadores y programadores hacen y sobre las que el líder de proyecto tiene, en general, un buen nivel de control.
Las fallas introducidas durante la fase de análisis de requerimientos pueden llevarnos a producir un sistema que nuestros clientes no nos ordenaron, por lo tanto, un sistema que nadie usará. En sistemas de misión crítica, las cosas son mucho peores, ya que estos errores pueden provocar accidentes. Para mitigar estos riesgos, se recomienda el uso de enfoques evolutivos para la especificación de requerimientos. La mayoría de las metodologías hoy en día soportan un ciclo de vida en forma de espiral, que entre otras cosas permite clarificar los requerimientos y da una visión más realista de lo qué hará el sistema. Para los sistemas de misión o seguridad crítica es también recomendable aplicar análisis de seguridad para determinar el riesgo asociado con la especificación de requerimientos y determinar si esto es aceptable o no. El análisis de seguridad nos da un estimado de cuál es el riesgo total del sistema. Si dicho riesgo no es aceptable, entonces se tienen que modificar los requerimientos o se deben tomar medidas de seguridad extras para reducir los riesgos.
El desarrollo e implementación del sistema también cae dentro del dominio del líder del proyecto, por lo que requiere de un gran entendimiento de los requerimientos y alcance del proyecto. Para líderes experimentados, este tipo de riesgos es marcado como moderado. Con esto no queremos decir que estos riesgos son poco importantes, al contrario, si el líder de proyecto no sigue una metodología bien soportada, o falla en la obtención del compromiso de la gente bajo su mando, algo saldrá mal. El sistema será entregado tarde (si es que es entregado), no cumplirá con los requerimientos, o en el mejor de los casos consumirá más recursos (tiempo, dinero, gente, outsourcing, etc.) Algunas estrategias para mitigar estos riesgos son el uso de un buen conjunto de métricas y herramientas de evaluación, herramientas para manejar costos y una clara división de responsabilidades entre el equipo de desarrollo.
Riesgos Fuera del Control del Líder de Proyecto
Los riesgos que están fuera del control del líder de proyecto son falta de compromiso de la gerencia, falta de compromiso de los usuarios y riesgos provocados por el ambiente (como conflictos entre distintos departamentos de usuarios, cambios en el alcance o metas del proyecto, cambios inesperados en el mercado, etc.). Los primeros dos, ya fueron mencionados con anterioridad. Los riesgos provocados por el ambiente, tienen una muy pequeña probabilidad de ocurrir, ya que se deben a cambios repentinos en el manejo de negocios, a los dueños de la empresa recortando el soporte financiero del proyecto, cambios en políticas internas que pueden afectar las metas originales, etc. Son difíciles de anticipar, y por lo tanto las estrategias de mitigación son tan sólo ideas un tanto vagas de lo que la gente ha recomendado en el pasado: planeo de contingencia y desastre. Cuando uno de estos riesgos se presenta, el sistema termina en un estado muy inconsistente, ya que al cambiar los alcances o las metas de un SBC en progreso, usualmente implica cambios mayores que afectan todas las partes del sistema. La mayoría de estos proyectos son abandonados, ya que su costo generalmente se duplica y el riesgo de tener más errores crece al menos un orden de magnitud por los modelos y el código heredados de la versión anterior del sistema.
Los papeles de administración de proyectos y diseño organizacional no son considerados -normalmente- cuando tratamos de mitigar riesgos. Afortunadamente esta visión ha comenzado a cambiar, con la aceptación y expansión de las áreas de manejo de conocimiento y organización. Esto nos permite comenzar a considerarlas como alternativas viables para mitigar los riesgos. Cabe aclarar que este tipo de estrategias funcionan sobre la organización misma, y no sobre un SBC en particular.
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Risks inside-out. MICAI 2000: Advances in Artificial Intelligence. Lectures Notes in Artificial Intelligence, Springer. No 1797, pp426-435. ISBN 3-540-67354-7. Ten Best Paper of MICAI-2000.
Cairó, O.; Barreiro, J. & Solsona, F. (1999). Software Methodologies at Risk. Lectures Notes in Artificial Intelligence, Springer. No 1621, pp323-329. ISBN 3-540-66044-5.
1.5 METRICAS
En la actualidad hay un gran número de herramientas y técnicas de ingeniería de conocimiento, desafortunadamente, cuando son evaluados sus beneficios no pueden ser demostrados. Cabe aclarar, que es un muy difícil encontrar métricas que permitan evaluar la efectividad del manejo del conocimiento. Las preguntas fundamentales que intentamos contestar en el trabajo son: ¿Qué debemos evaluar? y lo que es aún más importante ¿Cómo? La especificación de los objetos a ser evaluados es la piedra angular. Por ejemplo, supongamos que queremos evaluar una metodología de adquisición de conocimiento (MAC). ¿Cuál es el principal objeto de análisis: la metodología misma, los SBC desarrollados con ella o los beneficios derivados al aplicar dicho SBC?
Diseñamos un método de evaluación que involucra un proceso, al igual que muchos métodos de evaluación que le anteceden, y en esencia lo que buscamos es quedarnos con todo lo bueno de éstos. Nuestro método de evaluación se divide en cuatro pasos:
Nuestra intención con esta investigación no es ofrecer la métrica y la técnica de evaluación, sino propiciar más trabajo en esta área por parte de la comunidad de ingeniería del conocimiento. Revisamos los principios y los vertimos en un proceso de evaluación sólido y conciso.
Datos, Información y Conocimiento
Las expresiones datos, información y conocimiento son discutidos frecuentemente y siguen causando confusión entre miembros de nuestra comunidad. Davenport and Prusak capturan fielmente sus significados de la siguiente forma:
¿Cuánto debe Costar el Conocimiento?
En problemas de decisión, la información es considerada como económicamente valiosa. Es difícil tomar buenas decisiones en la ausencia de información, sin embargo, en ingeniería del conocimiento siempre hemos tenido que actuar a pesar de contar con información imprecisa o inexistente. Este problema es prácticamente inherente a cualquier dominio del conocimiento humano. El punto principal aquí es: ¿Cuánto tiempo debemos continuar el proceso de investigación para obtener el mejor balance entre el costo y el rendimiento de llevar a cabo investigación (identificar, monitorear y desarrollar información), y el valor que recibimos por evaluar el conocimiento?
En ingeniería de software, generalmente se utilizan la colección de procedimientos del valor de la información propuestos por Boehm. Sin embargo, en el mundo de la ingeniería de conocimiento obtener el mejor balance entre costo/información toma proporciones gigantescas, ya que el conocimiento obtenido es en la mayoría de los casos, incompleto o inadecuado.
La Especificación de Productos y Servicios
Debemos pensar en un mercado para el conocimiento. Esto es, no sólo en lo que el producto representa, sino también en lo que hace, y en los beneficios que trae a sus usuarios. Los clientes no están comprando un producto, están comprando la garantía de que el producto cumplirá sus expectativas. El concepto de valor está muy relacionado al principio de productos y servicios. El producto fue la razón para el boom de la actividad industrial, con dos caras diferentes. Primero, era el resultado de la manufactura, y segundo, la actividad industrial era un resultado que derivaba directamente del deseo o necesidad de un producto. Tradicionalmente el concepto de producto ha sido visto como una realidad tangible y presente al momento de la compra, mientras que los servicios considerados como intangibles, una promesa futura de lo que recibirá el cliente.
Hoy en día, parecería quedar en claro que hay un sólo concepto: producto como una colección de beneficios, con un valor específico para los clientes. Bajo estos nuevos términos, sólo hay productos que tienen un mayor o menor grado de servicios. En ingeniería del conocimiento, la información o el conocimiento agregado a los productos es un valor agregado.
Un Proceso General de Evaluación
Durante el desarrollo de cualquier SBC, distinguimos varias fases: la especificación de los requerimientos, un modelo inicial del sistema, la elicitación y adquisición del conocimiento, refinamientos al modelo inicial y la implementación del sistema. Estas fases están acotadas por una MAC, y por lo tanto, tenemos varios objetos de evaluación. Dichos objetos son evaluados externamente. Algunos de estos objetos son creados en etapas tempranas del proceso y viven muchas fases más.
¿Cómo podemos evaluar entonces el progreso de un SBC? Nuestro proceso general de evaluación sugiere ideas acerca de lo qué debe ser medido y cómo. Debe quedar claro que dar reglas específicas para aplicar a cualquier SBC es imposible, debido al conocimiento intrínseco. Cumplir con los requerimientos del SBC en una forma oportuna y dentro del presupuesto es la meta final, por lo que herramientas de estimación de tiempo y costos son indispensables. Estas herramientas son usadas para dos propósitos principales:
1.- Indicar puntos de prueba durante el desarrollo, en los cuáles se realizarán auditorias externas para revisar el progreso del sistema. V.gr. si elicitar conocimiento de múltiples fuentes fue estimado como una tarea que lleva de 2 a 3 semanas, entonces comprobar que el conocimiento ha sido elicitado en 3 semanas es bueno. Las técnicas que se usen para verificarlo están fuera del alcance de este trabajo, al igual que las herramientas particulares para estimar costos y tiempos. Sin embargo, la ventaja de este análisis es su independencia de tales herramientas precisamente.
2.- Las estimaciones de tiempo son también una buena herramienta para controlar la aplicabilidad general de la MAC usada. La mayoría de las metodologías modernas producen diagramas o modelos, a partir de los cuales puede ser fácilmente inferido el avance del proyecto (CommonKADS y KAMET, por ejemplo, generan diagramas de UML y modelos). La mayoría de las metodologías con un ciclo de vida en espiral tienen esta propiedad, ya que basan su comportamiento en un refinamiento incremental del modelo inicial.
Es importante resaltar el hecho de que estas revisiones periódicas de avance deben ser realizadas por grupos externos. Esto es, gente no relacionada con el desarrollo del sistema directamente. De esta forma podemos obtener reportes más confiables del progreso del sistema, además el líder de proyecto no es distraído de sus ocupaciones normales. Después de estas revisiones periódicas, las estimaciones de tiempo y costos totales deben ser ajustadas para evitar sorpresas. Nuevos puntos de evaluación son asignados.
La etapa final del desarrollo de SBC es la implementación y prueba del sistema. Primeramente, debemos medir que el sistema cumple los requerimientos (que debería ser una labor sencilla si cumplió con los avances parciales). En este momento, nuestro objeto de evaluación cambia y se convierte en el SBC mismo, los requerimientos, la metodología y todas las herramientas utilizadas en la creación pasan a un nivel secundario. El SBC debe ser evaluado en un contexto diferente: el mercado. Es aquí donde el cliente se convierte en el arbitro final de la calidad del sistema.
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Toward a Unified Evaluation Process forKnowledge-based Systems. (se va a enviar a una revista o conferencia internacional).
1.6 MODELACION DEL CONOCIMIENTO
El conocimiento adquirido de múltiples fuentes de conocimiento generalmente es extenso, impreciso, incompleto y desordenado; sistemática y cualitativamente. El principal problema parece ser una carencia de métodos para la adquisición y modelación del conocimiento, de herramientas para enfrentarse a estos métodos, y de conceptos acerca de como podríamos analizar e interpretar este conocimiento.
¿Qué tipo de método de modelación del conocimiento deberíamos formular? Debe enfocarse en realizar operaciones de razonamiento o ilustrar el proceso de entendimiento? Nuestro punto de vista es sencillo. Los modelos representan un puente entre el conocimiento y el razonamiento adquirido de múltiples fuentes de conocimiento (FC) y máquinas artificiales. Esto significa que el nivel de descripción debe tener un cierto nivel de abstracción, de tal forma que nos permita proporcionar coherencia en la interpretación del conocimiento y las futuras funciones del SBC. Confiamos en las ventajas de los modelos que ilustran el proceso de entendimiento. Las ventajas son casi absolutas, particularmente en áreas donde el conocimiento es extenso, impreciso, incompleto, y donde la adquisición del conocimiento se efectúa de múltiples FC. El modelo puede usarse como un medio de comunicación entre los Expertos Humanos (EH) y los IC, como una guía en la estructuración y descripción del conocimiento independientemente de su implementación y para evaluar estrategias de conocimiento. Representan además un punto intermedio entre el conocimiento adquirido de múltiples FC y el conocimiento representado en la base de conocimiento, y permiten la identificación y evaluación de los impactos positivos y negativos de un SBC.
Hay dos enfoques importantes en la modelación del conocimiento: el objetivista y el constructivista. El enfoque objetivista ve el conocimiento del experto como un volumen de información que puede ser transferido, prestado o almacenado. El enfoque constructivista define el conocimiento humano como un proceso cognitivo para el cual el problema a resolver se vuelve un artefacto. Clancey argumenta que el conocimiento no es independiente. Esto es en parte producto de la actividad, del contexto, y de la cultura en la cual se desarrolla. Nosotros seguimos este último enfoque.
Cabe señalar además que una teoría para modelación del conocimiento deber estar repleta con recomendaciones prácticas para el IC. El Ingeniero en Conocimientos debe confiar en que tiene el conocimiento experto del objeto que debe modelar, debe conocer y poder distinguir sus características y tipo existencia, y debe también tener una idea clara sobre cuáles son los objetivos del modelo que debe construir. El IC debe también tener sentido común, intuición, y la capacidad de hacer juicios apropiados. Aunque estas recomendaciones son indudablemente muy prácticas, no pueden ser exigidas en su totalidad e incorporadas fácilmente en una teoría de modelación. Los IC deben siempre recordar que la AC es una actividad de modelación, y ésta es considerada en la actualidad una actividad constructivista. Por lo tanto, ninguna solución total se puede encontrar.
Formalización: ¿Cómo?
La formalización refiere a una sintaxis explícita y a una semántica inequívoca para el término usado. La formalización de nuestro método de modelación del conocimiento se basa más en un metalenguaje que en un grupo terminante de teoremas y de pruebas matemáticas. Consideramos que la declaración en lenguaje formal es válida si y solo si la declaración en el campo de conocimiento es válida.
La estructura fina de los modelos se debe reflejar fielmente en la descripción formal correspondiente. Una vez que se indica la definición de los objetos atómicos en la formalización, resta por establecer la relación entre los objetos, y las reglas que relacionan uno con otro. Llamaremos a estas reglas, reglas de sintaxis, realzando el significado y el rango de la formalización. Estas relaciones son en general binarias, aunque en algunos casos pueden ser n-arias.
Las Suposiciones del LMC de KAMET
El lenguaje de modelación del conocimiento debe proporcionar un vocabulario rico en el cual el conocimiento y la experiencia se puedan expresar de manera apropiada. El conocimiento y el razonamiento deben ser modelados de forma tal, que los modelos se puedan explotar además en una manera muy flexible. El LMC de KAMET cubre conocimiento del dominio, conocimiento de inferencias y el conocimiento de tareas que conduce a un lenguaje que expresa los problemas de diagnóstico. El LMC tiene tres niveles de abstracción. El primero corresponde a constructores y componentes estructurales. Los constructores estructurales se utilizan para denotar el problema en sí. Dentro de los constructores estructurales, consideramos conveniente distinguir entre: problema, clasificación y subdivisión. Por otra parte, los componentes estructurales se utilizan para denotar las características y posibles soluciones de una alteración, desorden o anormalidad. Básicamente los componentes estructurales se descomponen en características y acciones. Las primeras se utilizan para determinar el diagnóstico y su posible solución. Dentro de características distinguimos: síntomas, antecedentes, solución, tiempo, valor, inexactitud. Las acciones indican que algo se tiene que llevar a cabo antes de continuar con el diagnóstico. Dentro de acciones se establecen diferencias entre los siguientes componentes estructurales: fórmula, estudio y proceso.
El segundo nivel de abstracción corresponde a los nodos y a las reglas de la composición. Las digráficas representan al modelo. Los elementos más importantes de una digráfica son sus vértices (nodos) y sus arcos (reglas de composición). Los constructores y los componentes estructurales forman los nodos. Distinguimos diversas clases de nodos: inicial, intermedio y terminal. Las reglas de composición, por su parte, son las que permiten la combinación adecuada de los constructores y de los componentes estructurales.
El tercer nivel de abstracción corresponde al modelo global. Consiste de al menos un nodo inicial, cualquier número de nodos intermedios, y uno o más nodos terminales. Un modelo global debe representar el conocimiento adquirido de múltiples FC en un dominio específico del conocimiento.
Hasta el momento el LMC ha sido descriptivo y expresado en un lenguaje informal que consiste de una mezcla del lenguaje natural estructurado, de diagramas y reglas de sintaxis. Esto conduce inevitablemente a la imprecisión en las definiciones de los componentes del LMC. Una descripción más formal del lenguaje quitaría cualquier ambigüedad e incluso exhibiría aquellas no vistas a primera vista. Sin embargo el uso de un lenguaje formal no nos conducirá a ninguna discusión de qué debe hacer una componente de un modelo. El uso de un lenguaje formal no es normativo, sino solamente descriptivo. Una vez que sea posible anotar todas las diferentes interpretaciones de una fuente del conocimiento en un lenguaje formal, los argumentos externos se deben utilizar para establecer cuáles de éstos es la versión más apropiada.
Una ventaja relacionada con quitar la ambigüedad, lo representa la facilidad de comunicación existente entre las etapas de KAMET. Esta se obtiene a través de la formalización de los modelos. Los modelos de conocimiento son lo principales medios de comunicación en varias etapas del proceso de desarrollo de KAMET, ambas entre el experto y el IC, y entre los diseñadores y los implementadores.
El LMC de KAMET tiende hacia un cálculo de predicados de primer orden extendido con algunas extensiones conservadoras. Una de ellas concierne a la sintaxis del lenguaje en sí mismo que usa una adaptación de un lenguaje orden-clasificado (order-sorted). Este es un lenguaje en el cual a todas las variables y constantes se les han asociado clasificaciones (los tipos), con tipos ordenados en una sub-clasificación jerárquica. Los predicados y las funciones también se tipifican (según los tipos de sus argumentos, y, para las funciones solamente sus resultados). Las reglas de inferencia de la lógica consideran que dos términos solamente pueden corresponder si hay lazos apropiados en la sub-clasificación entre sus clases. Estos incluyen la reducción del número de axiomas, la reducción de la longitud de fórmulas lógicas, un espacio reducido de búsqueda durante la deducción, y aumentar la legibilidad humana. Se presenta a continuación una representación funcional de las reglas de sintaxis del LMC de KAMET.
Reglas de sintaxis del LMC de KAMET
cml(structural).
cml(composition).
cml(indicator).
cml(chain).
structural(constructor).
structural(component).
constructor(problem).
constructor(classification).
constructor(subdivision).
component(time).
component(value).
component(symptom).
component(antecedent).
component(process).
component(formula).
component(inaccuracy).
component(examination).
component(solution).
value(indicator).
chain-element(symptom).
chain-element(antecedent).
chain-element(group).
chain(chain-element,...).
group(time,value,indicator,chain,...). ;; Riesgo de ciclo !!!
;; Reglas para los nodos
initial-node(symptom).
initial-node(antecedent).
initial-node(group).
initial-node(chain). ;; redundant.
intermediate-node(constructor).
intermediate-node(examination).
intermediate-node(process).
intermediate-node(formula).
intermediate-node(inaccuracy).
terminal-node(constructor).
;; Reglas de composición.
division(division-source,division-target).
division-source(problem).
division-source(symptom).
division-source(antecedent).
division-target(subdivision).
implication(implication-source,implication-target).
implication-source(problem).
implication-source(classification).
implication-source(symptom).
implication-source(antecedent).
implication-source(inaccuracy).
implication-target(problem).
implication-target(classification).
implication-target(symptom).
implication-target(antecedent).
implication-source(inaccuracy).
implication-target(solution).
union(subdivision,subdivision).
action(action-source,action-target).
action-source(problem).
action-source(symptom).
action-source(antecedent).
action-source(process).
action-source(examination).
Animación y Analizador de Sintaxis
El animador de modelos de KAMET es un interfaz interactiva para el LMC. Este es una notación semiformal de objetos para la especificación de los modelos del conocimiento de KAMET. Las partes del LMC se pueden entender y utilizar independientemente de KAMET. El LMC está soportado por un conjunto de herramientas. La herramienta más útil es el analizador de sintaxis del LMC, el cual es un programa independiente capaz de controlar las reglas de sintaxis del Lenguaje de Modelación Conceptual de KAMET. El analizador de sintaxis tiene la opción de generar la salida para otros programas. Verifica además la adherencia a las reglas de sintaxis de los objetos y de su coherencia. Seleccionamos scheme como nuestro lenguaje de programación, porque proporciona un lenguaje funcional con una extensión orientada a objetos.
A pesar de la simplicidad del LMC, un analizador de sintaxis es absolutamente necesario para controlar la sintaxis y saber si todo está correcto. El analizador de sintaxis de LMC se centra principalmente en preservar las reglas dinámicas de sintaxis del lenguaje. El analizador de sintaxis del LMC no requiere que la entrada de información contenga un modelo completo del conocimiento. Cualquier secuencia de construcciones que tenga su correspondiente estructura en scheme es aceptable para el analizador de sintaxis. A continuación se presenta parte del código de animación:
;;; <cml.ss> ---- KAMET Conceptual Modeling Language simulation.;
;; Commentary: Under construction.
;;
(define cml<%> (interface () description))
(define cml%
(class* object% (cml<%>) ()
(public
[name 'cml]
[description "No description available"]
[print-name (lambda ()
(display name) (newline))]
[print-description (lambda ()
(display description) (newline))]
)
(sequence super-init)))
(define composition<%> (interface () description source target))
(define composition%
(class* cml% (composition<%>) ()
(inherit description)
(override
[name 'composition])
(public
[source null]
[target null])
(sequence super-init)))
(define structural<%> (interface () description))
(define structural%
(class* cml% (structural<%>) ()
(inherit description)
(override
[name 'composition])
(sequence super-init)))
(define indicator<%> (interface () minimum maximum))
(define indicator%
(class* cml% (indicator<%>) (min max)
(inherit description)
(override
[name 'indicator])
(public
[minimum min]
[maximum max])
(sequence super-init)))
;; Structural's
(define component%
(class structural% ()
(inherit description)
(override
[name 'structural-component])
(public
[indicator (make-object indicator% 1 1)])
(sequence super-init)))
(define constructor%
(class structural% ()
(inherit description)
(override
[name 'structural-constructor])
(sequence super-init)))
;; Structural Components
(define time%
(class component% (time-description)
(override
[name 'time]
[description time-description])
(sequence super-init)))
(define value%
(class component% (value-description)
(override
[name 'value]
[description value-description])
(sequence super-init)))
(define symptom<%> (interface () time value))
(define symptom%
(class* component% (symptom<%>) (symptom-description)
(override
[name 'symptom]
[description symptom-description])
(public
[time (make-object time%)]
[value (make-object value%)])
(sequence super-init)))
(define antecedent<%> (interface () time value))
(define antecedent%
(class* component% (antecedent<%>) (antecedent-description)
(override
[name 'antecedent]
[description antecedent-description])
(public
[time (make-object time%)]
[value (make-object value%)])
(sequence super-init)))
(define inaccuracy%
(class component% (inaccuracy-description)
(override
[name 'inaccuracy]
[description inaccuracy-description])
(sequence super-init)))
(define process%
(class component% (process-description)
(override
[name 'process]
[description process-description])
(sequence super-init)))
(define formula%
(class component% (formula-description)
(override
[name 'formula]
[description formula-description])
(sequence super-init)))
(define examination%
(class component% (examination-description)
(override
[name 'examination]
[description examination-description])
(sequence super-init)))
(define solution%
(class component% (solution-description)
(override
[name 'solution]
[description solution-description])
(sequence super-init)))
;; Structural Constructors
(define problem<%> (interface () time))
(define problem%
(class* constructor% (problem<%>) (problem-description)
(override
[name 'problem]
[description problem-description])
(public
[time (make-object time%)])
(sequence super-init)))
(define classification%
(class constructor% (classification-description)
(override
[name 'classification]
[description classification-description])
(sequence super-init)))
(define subdivision<%> (interface () time))
(define subdivision%
(class* constructor% (subdivision<%>) (subdivision-description)
(override
[name 'subdivision]
[description sudivision-description])
(public
[time (make-object time%)])
(sequence super-init)))
;; Composition's
(define division%
(class composition% (arc-source arc-target)
(override
[name 'division]
[source arc-source]
[target arc-target])))
(define implication%
(class composition% (arc-source arc-target)
(override
[name 'implication]
[source arc-source]
[target arc-target])))
(define action%
(class composition% (arc-source arc-target)
(override
[name 'action]
[source arc-source]
[target arc-target])))
(define union%
(class composition% (arc-source arc-target)
(override
[name 'union]
[source arc-source]
[target arc-target])))
;;; cml.ss ends here
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Conceptual Modeling Language Formalization and Animation. (se va a enviar a una revista o conferencia internacional).
1.7 CONCLUSIONES SOBRE KAMET
En esta primera sección presentamos una metodología de la adquisición de conocimiento de fuentes múltiples del conocimiento. La meta principal de KAMET es mejorar, en un cierto sentido, tanto la fase de adquisición del conocimiento, como el proceso de modelación del conocimiento. Hay dos ideas fundamentales en KAMET. La primera se asocia al proceso de adquisición de conocimiento en sí mismo. La segunda se relaciona fuertemente con el conocimiento que modela el método aquí presentado. El LMC todavía está experimentando revisiones, en particular debido a investigar las reglas de sintaxis que corresponden a modelar el conocimiento verdadero del mundo. Sin embargo, las características principales de este lenguaje parecen ser bastante estables como para evolucionar hacia una estrategia de modelación ampliada del conocimiento.
Indudablemente, KAMET se ha beneficiado directamente del desarrollo de técnicas y herramientas para catalogación y mitigación de riesgos, del proceso general de evaluación, del LMC y UML. Todos los resultados que hemos obtenido han sido incorporados a KAMET. Esperamos que en el futuro cercano estas ventajas se traduzcan en una metodología capaz de guiar a los usuarios de manera más transparente durante el largo y muchas veces sinuoso camino de la construcción de SBC. Aún resta mucho por hacer, necesitamos afinar detalles complejos de la metodología y revisar nuestros métodos y resultados parciales obtenidos hasta a fecha.
2. PRODUCTIVIDAD
Se describe en la siguiente sección la productividad lograda, con el apoyo de REDII, en el período 1998-2000.
2.1. FORMACION DE RECURSOS HUMANOS
Uno de los objetivos del proyecto es la formación de recursos humanos de alta calidad. Por una parte, en el presente, capaces de participar activamente en hot topics; y por otra parte, capaces de convertirse en el futuro en profesionales exitosos y/o investigadores de prestigio en México.
El Fis. Julio Barreiro y el Lic. Francisco Solsona participan activamente en el proyecto de investigación del cuál soy responsable. Juntos hemos escrito artículos que han sido publicados en revistas internacionales de calidad -las referencias se presentan en la sección 2.3-, e incluso ganado un premio como best paper en una Conferencia Internacional. Ambos se encuentran en la actualidad en la fase final de su carrera, trabajando en este proyecto, y esperando el próximo año para irse al exterior a realizar su doctorado.
Respecto a la dirección de tesis, las mismas se presentan a continuación:
Tesis de Maestría
Tejedas, Alejandro. (1999). Diseño de un Sistema de Detección de Intrusión Computacional Militar, Aplicando Técnicas de Inteligencia Artificial. Tesis de Maestría. Instituto Tecnológico y de Estudios Superiores de Monterrey. Campus Estado de México. (en proceso).
Díaz, Jorge. (1999). El uso y efecto de herramientas de groupware en empresas Mexicanas. Tesis de Maestría. Instituto Tecnológico y de Estudios Superiores de Monterrey. Campus Monterrey. (en proceso).
Tesis de Doctorado (Miembro del Comité Doctoral)
Padilla, Felipe. (1998). Modelo para la creación de aplicaciones con Algoritmos Genéticos. Tesis de Doctorado. Facultad de Ingeniería. Universidad Nacional Autónoma de México. (en proceso).
Mora Tavarez, José. (1999). Título: sin registrar. Area: Administración del Conocimiento y Sistemas Basados en Conocimientos. Tesis de Doctorado. Facultad de Ingeniería. Universidad Nacional Autónoma de México. (en proceso).
Alvarez, Francisco. (1999). Título: sin registrar. Area: Administración del Conocimiento. Tesis de Doctorado. Facultad de Ingeniería. Universidad Nacional Autónoma de México. (en proceso).
2.2. EDUCACION
Durante el período correspondiente se estuvo trabajando en dos proyectos relativos a educación: dos libros de texto. En ambos, en la segunda edición del libro. Se describen brevemente ambos proyectos.
Estructuras de Datos
Cairó, O. & Guardati, S. (1993). Estructuras de Datos. McGraw-Hill. ISBC 970-10-0258-X.
El libro de Estructuras de Datos ha sido considerado uno de los best sellers de la editorial, en esta área del conocimiento. Actualmente se han vendido más de 12,000 ejemplares y hemos sido invitados para escribir la segunda edición del libro. Esta segunda edición presentará los algoritmos revisados más importantes de las estructuras de datos y un nuevo capítulo referente a gráficas. Se presenta a continuación, brevemente, los objetivos del libro:
Estructura de Datos: Objetivo
Este libro tiene como objetivo presentar las estructuras de datos, así como los algoritmos necesarios para tratarlas. El lenguaje utilizado para ello es algorítmico, independiente de cualquier lenguaje de programación. Esta característica es muy importante, ya que permite al lector comprender las estructuras de datos y los algoritmos asociados a ellas sin relacionarlos a lenguajes de programación particulares. Se considera que una vez que el lector domine estos conceptos, podrá implementarlos fácilmente en cualquier lenguaje.
Si bien cada uno de los temas son desarrollados de niveles simples a niveles complejos, se supone que el lector ya conoce ciertos conceptos, por ejemplo el de datos simples (enteros, reales, booleanos, carácter); el de instrucción (declarativa, asignación, entrada/salida), y el de operadores (aritméticos, relacionales y lógicos). Asimismo se utiliza, pero no se expone, el concepto de variables y constantes. En los algoritmos se escriben los nombres de variables con mayúsculas (SUMA, N, etc.), lo mismo para las constantes booleanas (VERDADERO y FALSO).
Cabe aclarar que en este libro no se abordan los tipos abstractos de datos de manera explícita. Sin embargo, se tratan algunos de ellos sin presentarlos como tales; por ejemplo, las pilas y colas en el capítulo tres. Finalmente, cabe aclarar que cada capítulo cuenta con un número importante de ejercicios. Con éstos se sigue el mismo criterio aplicado en el desarrollo de los distintos temas, es decir, se proponen ejercicios en los que se aumenta gradualmente el nivel de complejidad.
Estructura de Datos: Estructuras Utilizadas.
El lenguaje utilizado para describir los algoritmos es estructurado. Las estructuras se enumeran y las instrucciones que forman parte de ellas se escriben dejando sangrías para dar mayor claridad. También, con el objeto de ayudar al entendimiento de los mismos, se escriben comentarios encerrados entre {}. A continuación se presentan las estructuras empleadas en los algoritmos:
Condicional básica
pi -Si condición entonces
acción
p(i + 1) -{ Fin del condicional del paso pi }
Donde condición es cualquier expresión relacional y/o lógica, y acción es cualquier operación o conjunto de operaciones (lectura, escritura, asignación u otras). Esta estructura permite seleccionar una alternativa dependiendo de que la condición sea verdadera. Es decir, al ser evaluada la condición, si ésta es verdadera, entonces se ejecutará la acción indicada.
Condicional doble
pi -Si condición
entonces
acciónl
sino
acción2
p(i + 1 )- { Fin del condicional del paso pi }
Donde condición es cualquier expresión relacional y/o lógica, y acción1 y acción2 son cualquier operación o conjunto de operaciones (lectura, escritura, asignación u otras). Esta estructura permite seleccionar una de dos alternativas, según la condición sea verdadera o falsa. Si la condición es verdadera se ejecutará la acción 1, en caso contrario se ejecutará la acción2.
Condicional múltiple
pi- Si variable
= valor1: acción1
= valor2: acción2
.
.
.
= valorn: acciónn
p(i + 1 )- { Fin del condicional del paso pi }
Donde valorj, 1 £ j £ n, son los posibles valores que puede tomar la variable; acciónj, 1 £ j £ n, es cualquier operación o conjunto de operaciones (lectura, escritura, asignación u otras). Este tipo de estructura se utiliza para una selección sobre múltiples alternativas. Según el valor de la variable se ejecutará la acción correspondiente. Así, si variable es igual a valor1 se ejecutará la acción1, si variable es igual a valor2 se ejecutará la accción2 y así en los demás casos.
Iterativa condicionada
pi- Repetir mientras condición
acción
p(i + 1)- { Fin del ciclo del paso pi}
Donde condición es cualquier expresión relacional y/o lógica, y acción es cualquier operación o conjunto de operaciones (lectura, escritura, asignación u otras). Esta estructura permite repetuir una o más operaciones mientras la condición sea verdadera.
Iterativa predefinida
pi- Repetir con variable desde VI hasta VF
acción
p(i + 1)- { Fin del ciclo del paso pi}
Donde variable es cualquier variable, VI es un valor inicial que se le asigna a variable, VF es el valor final que va a tomar variable y acción es cualquier operación o conjunto de operaciones (lectura, escritura, asignación u otras). Esta estructura permite repetir una o más operaciones un número fijo de veces. El número de repeticiones queda determinado por la diferencia entre VF y VI más uno.
Metodología de la Programación
Cairó, O. (1996). Metodología de la Programación: Algoritmos, Diagramas de Flujo y Programas. Volumen 2. Editorial Alfaomega. ISBN 970-15-0058-X.
Cairó, O. (1995). Metodología de la Programación: Algoritmos, Diagramas de Flujo y Programas. Volumen 1. Editorial Alfaomega. ISBN 970-15-0057-1.
El libro de Metodología de la Programación ha sido considerado un libro interesante por parte de la gente de la editorial, ya que se han vendido desde 1995 -fecha en que aparece el primer volumen- alrededor de 7,000 ejemplares. A la fecha, he sido invitado para escribir la segunda edición del libro, más compacta que la anterior, y en un solo volumen. El lenguaje utilizado -pseudocódigo- será suficientemente flexible para que la solución de los problemas pueda transportarse fácilmente a los lenguajes de programación actuales. Se presenta a continuación, brevemente, los objetivos del libro:
Metodología de la Programación: Objetivo
Esta obra está dirigida a todos aquellos que por alguna razón necesitan solucionar problemas de tipo algorítmico, aplicando razonamiento basado en la lógica. La motivación para escribir este libro surgió al dictar repetidamente cursos introductorios en carreras de computación, donde fundamentalmente se trata que los alumnos apliquen un razonamiento sistemático, basado en la lógica, para resolver problemas de tipo algorítmico, independientemente de un lenguaje de programación. Aunque reuní bibliografía relativa a los tópicos señalados, encontraba que la misma era obsoleta, y en algunos casos deficiente. Identifiqué entonces la necesidad de contar con una obra que pudiera ofrecer una alternativa moderna y estructurada a profesores y alumnos involucrados en este tipo de cursos.
Haciendo una clasificación muy general, los problemas pueden ser divididos en dos tipos, aquellos que requieren de un tratamiento algorítmico para su solución y aquellos que necesitan de una búsqueda para poder ser solucionados. En esta obra abordaremos problemas del primer tipo. Estos se caracterizan por la necesidad de un análisis profundo y sistemático, y de un pensamiento flexible y estructurado para alcanzar su solución. Inevitablemente surgen ciertos cuestionamientos:
¿Podemos enseñar a resolver un problema?
¿Podemos enseñar a analizar al mismo?
¿Podemos enseñar a pensar?
Las respuestas a estas interrogantes son difíciles de encontrar, pero justamente es lo que se pretende alcanzar en este proyecto. Se sabe que no existen reglas específicas para resolver un problema, sin embargo, se considera que se pueden ofrecer un conjunto de técnicas y herramientas metodológicas que permitan flexibilizar y estructurar el razonamiento seguido por un alumno en la solución de un problema. Inevitablemente, se necesitará de la cooperación del maestro para alcanzar este objetivo. Pero, por otra parte, se parte que es nuestra responsabilidad como profesores enseñar e inducir al alumno a observar el problema desde diferentes ángulos, a ser flexibles en el razonamiento que conduzca a su solución, a no encerrarse en un solo punto de vista, a tener una mente crítica y a tener una metodología bien estructurada para poder atacar los problemas. Otra característica importante del libro la constituye el tipo de lenguaje que se utiliza para la construcción de los programas. Este es un lenguaje algorítmico, estructurado, escrito en pseudocódigo, independiente de cualquier lenguaje de programación. Esto es importante, ya que permite al lector comprender las estructuras de datos y los algoritmos asociados a ellas sin necesariamente relacionarlos con un lenguaje de programación en particular. Una vez que el lector domine los conceptos expuestos en este libro, muy fácilmente podrá transportar los programas realizados a un lenguaje de programación de alto nivel.
La obra está dividida en cuatro capítulos. En cada uno de los mismos aumenta en forma gradual, el nivel de complejidad de los temas tratados. Además, los temas son expuestos con amplitud y claridad. El aprendizaje se reafirma con la gran cantidad de ejercicios diseñados expresamente. Como elementos de ayuda para el análisis y la retención de los conceptos se utilizan tablas con seguimientos de los algoritmos con el fin de presentar cómo funcionan éstos y de qué manera afectan las estructuras algorítmicas de control y las estructuras de datos que se estudian.
2.3. ARTICULOS Y PUBLICACIONES
Libros de Texto
Cairó, O. (2001). Metodología de la Programación: Algoritmos, Diagramas de Flujo y Programas. 2da. Edición. Editorial Alfaomega. (aceptado para ser publicado).
Cairó, O. & Guardati, S. (2001). Estructuras de Datos. McGraw-Hill. (aceptado para ser publicado). Nota: Uno de los libros de mayor éxito de la editorial en el área de Estructuras de Datos. Más de 12,000 ejemplares vendidos.
Contribuciones en Libros
Cairó, O.; Cervantes, F.; Reyes, L.; Violante, A. & García, E. (1998). HeadExpert: A Knowledge Based System for the Diagnosis of Headache Disorders, Cranial Neuralgia´s, and Facial Pain. Technology Transfer Guidebook Series. Jacobs & Niku-Lari (Eds.) USA. ISBN 2-90766936-2.
Revistas y Conferencias Internacionales
Cairó, O.; Barreiro, J. & Solsona, F. (2000). The Importance of Metrics and Evaluation Processes in Knowledge-Based Systems. The 2nd International Workshop on Computer Science and Information Technologies. Ufa, Russia. (aceptado para publicación).
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Risks inside-out. MICAI 2000: Advances in Artificial Intelligence. Lectures Notes in Artificial Intelligence, Springer. No 1797, pp426-435. ISBN 3-540-67354-7. Ten Best Paper of MICAI-2000.
Cairó, O.; Barreiro, J. & Solsona, F. (1999). Software Methodologies at Risk. Lectures Notes in Artificial Intelligence, Springer. No 1621, pp323-329. ISBN 3-540-66044-5.
Cairó, O. (1998). KAMET: A Comprehensive Methodology for Knowledge Acquisition from Multiple Knowledge Sources. Expert System with Applications, 14(1/2), pp1-16. Pergamon. ISSN 0957-4174.
Cairó, O. (1998a). The KAMET Methodology: Content, Usage and Knowledge Modeling. In Gaines, B. & Mussen, M. (Eds.). Proceedings of the 11th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW´98). SRGD Publications, Department of Computer Science, University of Calgary. Proc-1, pp1-20.
Revistas Nacionales
Cairó, O. (2000). Inteligencia Artificial e Inteligencia Natural. Soluciones Avanzadas. Año 7, Nro. 75, pp34-35. ISSN 0188-8048. (Artículo de Divulgación).
En Preparación…
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Conceptual Modeling language Formalization and animation. (se va a enviar a una revista o conferencia internacional).
Cairó, O.; Barreiro, J. & Solsona, F. (2000). Toward a unified evaluation process for knowledge based systems. (se va a enviar a una revista o conferencia internacional).
2.6. DESARROLLO DE GRUPOS DE INVESTIGACION
Se describe brevemente la formación de un grupo de investigación. Actualmente, estamos en tratativas para realizar un proyecto en forma conjunta con la Universidad Politécnica de Madrid, de España, y la Universidad de Amsterdam en Holanda. Esto permitirá la generación de tesis como parte del proyecto y la formación de recursos humanos de alta calidad. Ambos, Julio y Francisco se irán a realizar el doctorado el próximo año. Roberto López quién colaboró en el proyecto en sus incios está actualmente realizando el doctorado en la Universidad de Texas, en Austin.
|
Líderes |
: |
Dr. Osvaldo Cairó. Participantes: Fis. Julio Barreiro, Lic. Francisco Solsona. |
|
Objetivo |
: |
El desarrollo de una metodología para la adquisición del conocimiento de múltiples fuentes de conocimientos. |
|
Impacto |
: |
Formación de recursos humanos (tesis). Aportaciones a la comunidad internacional. Publicación de artículos en revistas, conferencias y workshops internacionales. Ver publicaciones. |
|
Patrocinio |
: |
Parcial a través de CONACYT (Proyecto Nro. D.A.J.-J002-222-98-16-II-98 - REDII) |
|
Vigencia |
: |
1998 - Presente. |
5. EVENTOS ORGANIZADOS
Se describen a continuación la organización de eventos en los cuáles he estado invlucrado durante el período correspondiente.
MICAI-2000. The First Mexican International Conference on Artificial Intelligence. Acapulco, Mexico. 10-14 Abril, 2000.
IBERAMIA-2000. 7th Ibero-American Conference on Artificial Intelligence. Sao Paulo, Brasil. 19-22 Noviembre, 2000.
IJCAI-2003. Eighteen International Joint Conference on Artificial Intelligence IJCAI-03. Acapulco, Mexico.
Se presenta a continuación un breve reporte sobre MICAI-2000, del cúal además de ser organizador del evento, participé en otras actividades como se presentó anteriormente.
MICAI es la unión de la Reunión Nacional de Inteligencia Artificial (RNIA) y el Simposium Internacional sobre Inteligencia Artifical, organizados respectivamente por la Sociedad Mexicana de Inteligencia Artificial (SMIA, desde 1984) y el Instituto Tecnológico y de Estudios Superiores de Monterrey (ITESM, desde 1988). La primer Conferencia Internacional sobre Inteligencia Artificial, MICAI-2000, se llevó a cabo en la Ciudad de Acapulco, del 10-14 de Abril del corriente año. Esta conferencia busca promover la investigación en Inteligencia Artificial entre los investigadores mexicanos y sus pares del mundo entero. Cabe aclarar que en MICAI 2000 se llevaron a cabo además dos eventos: el III Taller de Inteligencia Artificial (TAINA-2000) y el V Taller Iberoamericano de Reconocimiento de Patrones (TIARP-2000), eventos tradicionalmente patrocinados por la SMIA y organizados por el Centro de Investigación en Computación (SIC) del Instituto Politécnico Nacional (IPN).
Más de 160 artículos de 17 países del mundo fueron sometidos a consideración para MICAI 2000. Después de revisar cuidadosamente a ellos, el Comité de Programa de MICAI, referís y Program Chair, aceptaron 60 artículos para el track internacional. El volumen de Lectures Notes in Artificial Intelligence de Springer-Verlag, contiene todos estos artículos, además de los artículos respectivos de algunas conferencias invitadas presentadas en MICAI. 40 artículos más fueron aceptados para el track en español. Estos artículos fueron publicados por el Centro de Investigación en Computación.
6. RECONOCIMIENTOS DEL PERIODO
Se describe brevemente a continuación algunos reconocimientos obtenidos durante el período.